(*: indicates joint first authors)
Yan Zhao 1 Hao Dong1Articulated objects (e.g., doors and drawers) exist everywhere in our life. Different from rigid objects, articulated objects have higher degrees of freedom, and are rich in geometries, semantics and part functions. Modeling different kinds of parts and articulations plays an essential role in articulated object understanding and manipulation, and will further benefit 3D vision and robotics communities. To model articulated objects, most previous works directly encode articulated objects into feature representations, without specific designs for parts, articulations and part motions. In this paper, we introduce a novel framework that disentangles the part motion of articulated objects by predicting the transformation matrix of points on the part surface, using spatially continuous neural implicit representations to model the part motion smoothly in the space. Besides, while many methods could only model a certain kind of joint motion (such as the revolution in the clockwise order), our proposed framework is generic to different kinds of joint motions in that transformation matrix can model diverse kinds motions in the space. Quantitative and qualitative results of experiments over diverse categories of articulated objects demonstrate the effectiveness of our proposed framework.
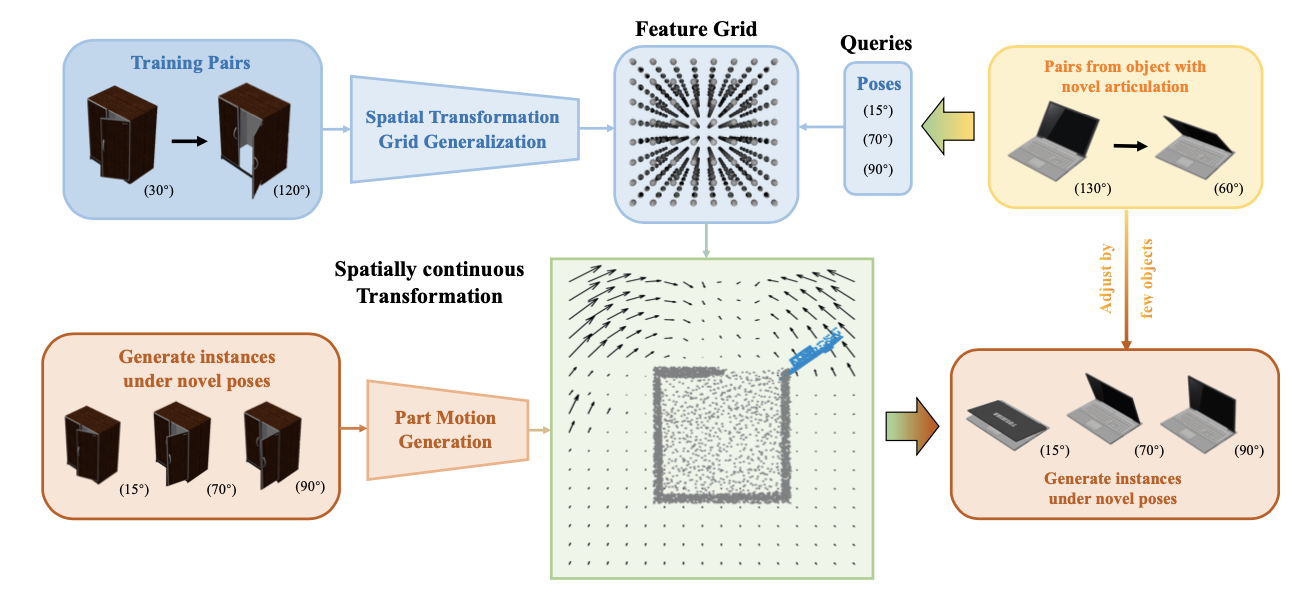
Figure 1. There are a plethora of 3D objects around us in the real world. Compared to those rigid objects with only 6 degrees of freedom (DoF), articulated objects (\emph{e.g.}, doors and drawers) additionally contain semantically and functionally important articulated parts (\emph{e.g.}, the screen of laptops), resulting in their higher DoFs in state space, and more complicated geometries and functions. Therefore, understanding and representing articulated objects with diverse geometries and functions is an essential but challenging task for 3D computer vision. |
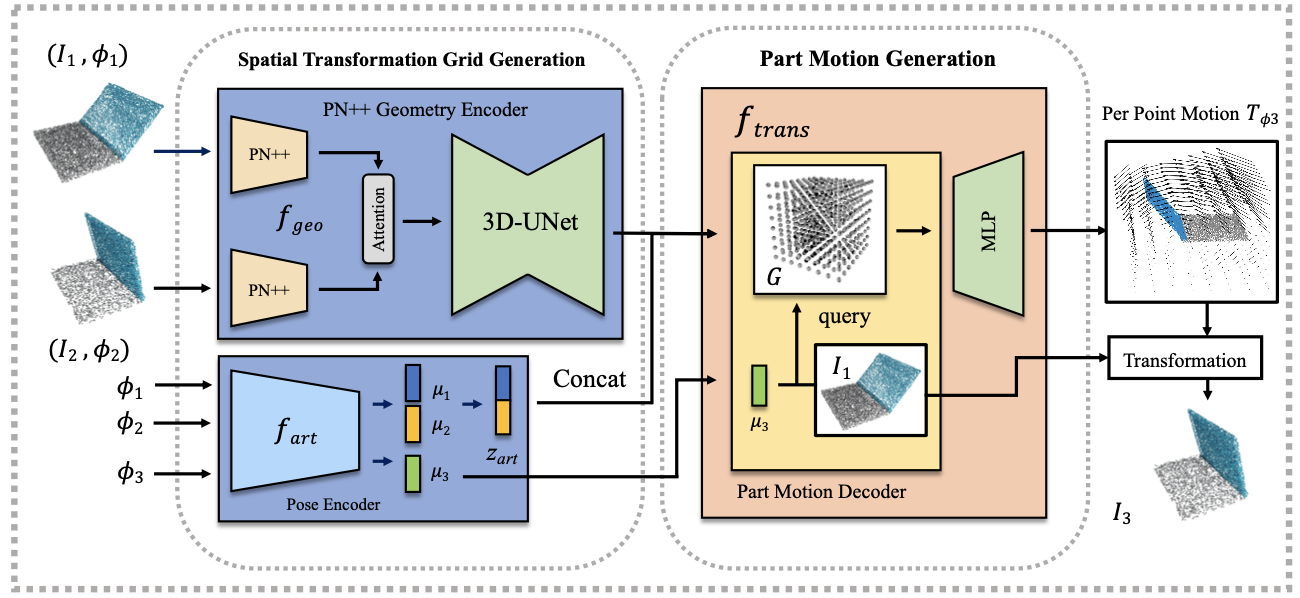
Figure 2. Overview of our proposed framework Our proposed framework receives two point clouds from the same articulated object under two different part poses. Then generate the object point cloud with a new part pose. It aggregates the geometric information and the pose information into a spatially continuous Transformation Grid. During inferencing, conditioned on the new part pose, it decodes the transformation of each point by querying each point in the Grid to generate the input object with the novel pose. |
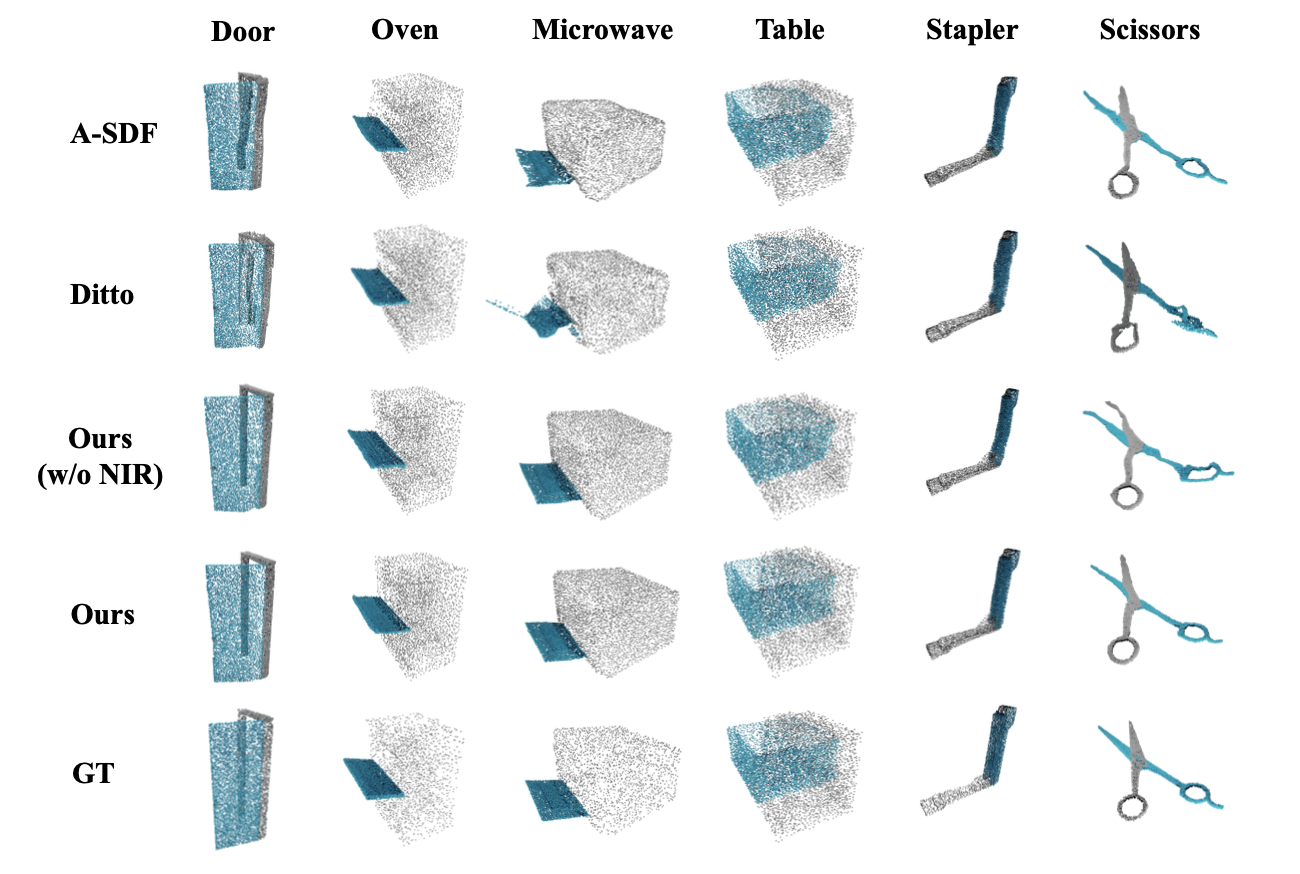
Figure 3. Qualitative results The results show that our method reserves the most detailed geometries of both articulated parts and object bases. For example, our model predicts the straightest door frame and the smoothest microwave door surface. |
If you have any questions, please feel free to contact Yushi Du at duyushi628_at_pku_edu_cn and Ruihai Wu at wuruihai_at_pku_edu_cn.
@InProceedings{du2023learning, author = {Du, Yushi and Wu, Ruihai and Shen, Yan and Dong, Hao}, title = {Learning Part Motion of Articulated Objects Using Spatially Continuous Neural Implicit Representations}, booktitle = {British Machine Vision Conference (BMVC)}, month = {November}, year = {2023} }